In this work, we propose the "Label Transfer" problem, where a label transfer model needs to adjust the source labels such that the tranferred labels follow the annotation protocol in the target dataset. We evaluate the effectiveness by the performances of the induced downstream detectors.
Main challenge: there is no paired labels on the same image in the datasets.
Label-Guided Pseudo-Labeling (LGPL)
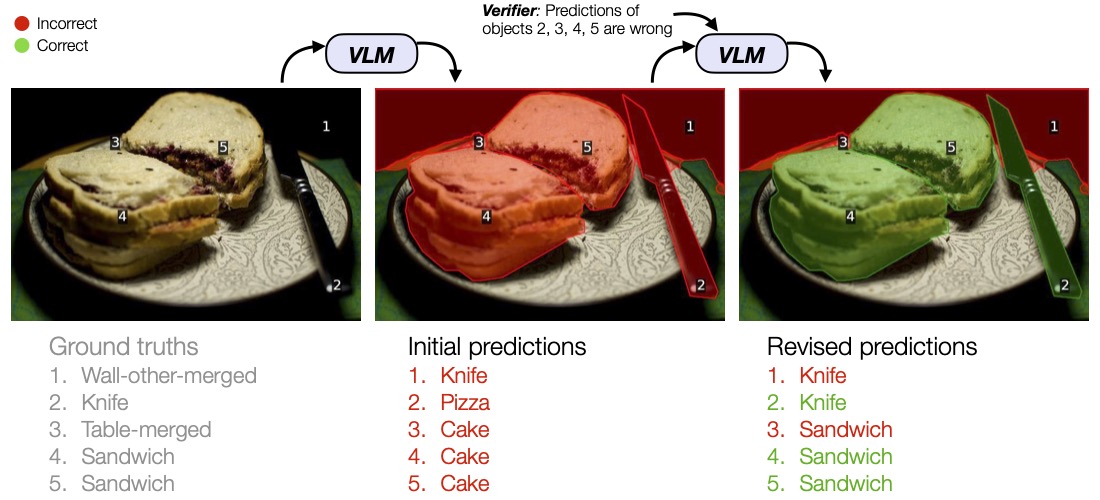
To mitigate annotations mismatches, we may use a model trained on the target data to generate pseudo-labels on the source images (Arazo et al., 2019; Lee, 2013), but this discards the existing source labels. On the other hand, statistical normalization (Wang et al., 2020) aligns boxes statistics but ignores the image content. Label-guided pseduo-lableing aims to fully leverate all available information for the label transfer problem
LGPL is inspired by identifying that the strategy used in two-stage object detectors. In short, we trained the RPN network on the source datasets and apply source-trained RPN to produce source-like proposals on the target images. Finally, we train the RoI head to transfer the source-like proposals on the target images to the target labels. All the components can be trained end-to-end.