publications
2025
- LongPerceptualThoughts: Distilling System-2 Reasoning for System-1 PerceptionYuan-Hong Liao, Sven Elflein , Liu He , Laura Leal-Taixé , Yejin Choi , Sanja Fidler , and David AcunaIn Second Conference on Language Modeling , 2025
Recent reasoning models through test-time scaling have demonstrated that long chain-of-thoughts can unlock substantial performance boosts in hard reasoning tasks such as math and code. However, the benefit of such long thoughts for system-2 reasoning is relatively less explored in other domains such as perceptual tasks where shallower, system-1 reasoning seems sufficient. In this paper, we introduce LongPerceptualThoughts, a new synthetic dataset with 30K long-thought traces for perceptual tasks. The key challenges in synthesizing elaborate reasoning thoughts for perceptual tasks are that off-the-shelf models are not yet equipped with such thinking behavior and that it is not straightforward to build a reliable process verifier for perceptual tasks. Thus, we propose a novel three-stage data synthesis framework that first synthesizes verifiable multiple-choice questions from dense image descriptions, then extracts simple CoTs from VLMs for those verifiable problems, and finally expands those simple thoughts to elaborate long thoughts via frontier reasoning models. In controlled experiments with a strong instruction-tuned 7B model, we demonstrate notable improvements over existing visual reasoning data-generation methods. Our model, trained on the generated dataset, achieves an average +3.4 points improvement over 5 vision-centric benchmarks, including +11.8 points on V* Bench. Notably, despite being tuned for vision tasks, it also improves performance on the text reasoning benchmark, MMLU-Pro, by +2 points.
@inproceedings{liao2025longperceptualthoughts, title = {LongPerceptualThoughts: Distilling System-2 Reasoning for System-1 Perception}, author = {Liao, Yuan-Hong and Elflein, Sven and He, Liu and Leal-Taixé, Laura and Choi, Yejin and Fidler, Sanja and Acuna, David}, booktitle = {Second Conference on Language Modeling}, url = {https://arxiv.org/abs/2504.15362}, year = {2025} } -
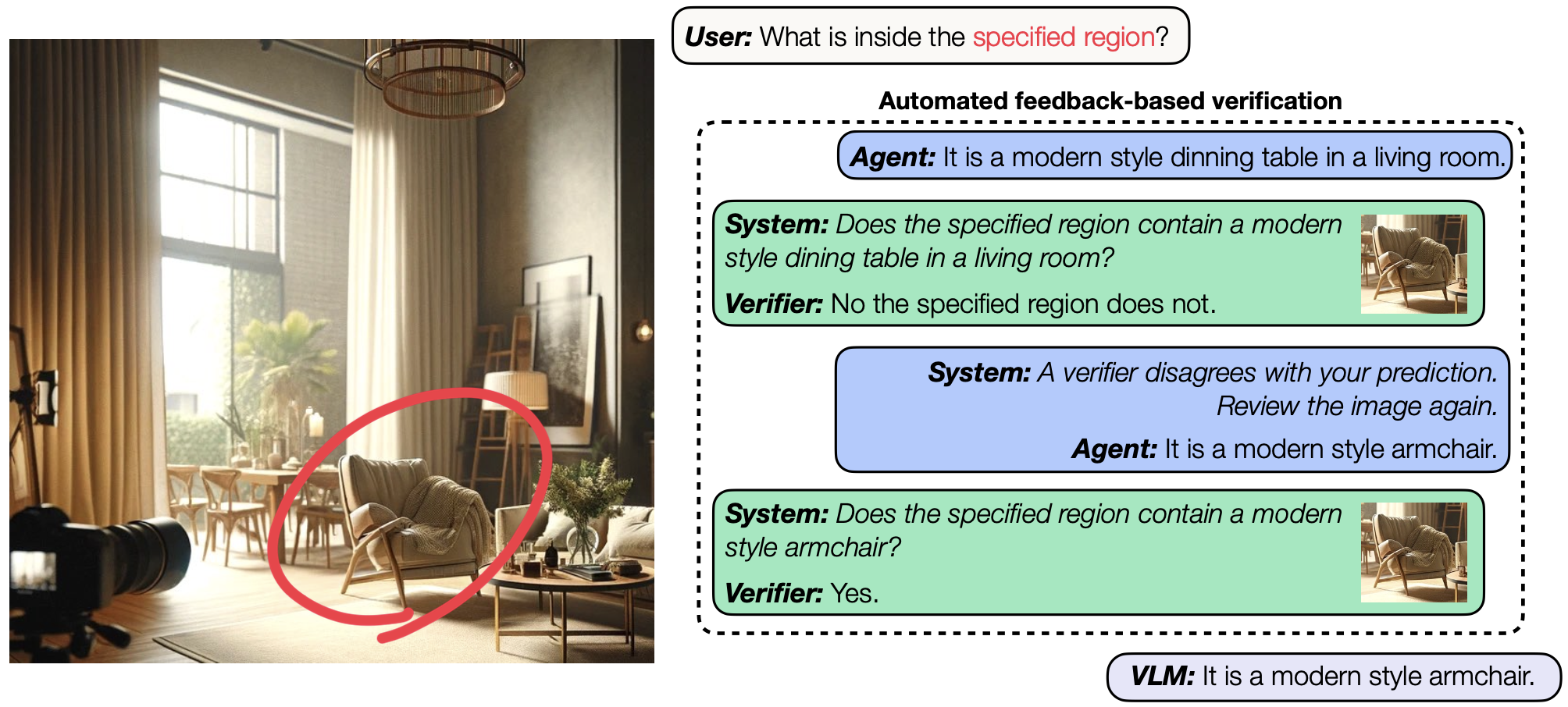 Can Large Vision-Language Models Correct Semantic Grounding Errors By Themselves?Yuan-Hong Liao, Rafid Mahmood , Sanja Fidler , and David AcunaIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2025
Can Large Vision-Language Models Correct Semantic Grounding Errors By Themselves?Yuan-Hong Liao, Rafid Mahmood , Sanja Fidler , and David AcunaIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2025Enhancing semantic grounding abilities in Vision-Language Models (VLMs) often involves collecting domain-specific training data, refining the network architectures, or modifying the training recipes. In this work, we venture into an orthogonal direction and explore whether VLMs can improve their semantic grounding by "receiving" to feedback 💬, without requiring in-domain data, fine-tuning, or modifications to the network architectures. We systematically analyze this hypothesis using a feedback mechanism composed of a binary signal. We find that if prompted appropriately, VLMs can utilize feedback both in a single step and iteratively, showcasing the potential of feedback as an alternative technique to improve grounding in internet-scale VLMs. Furthermore, VLMs, like LLMs, struggle to self-correct errors out-of-the-box. However, we find that this issue can be mitigated via a binary verification mechanism. Finally, we explore the potential and limitations of amalgamating these findings and applying them iteratively to automatically enhance VLMs’ grounding performance, showing grounding accuracy consistently improves using automated feedback across all models in all settings investigated. Overall, our iterative framework improves semantic grounding in VLMs by more than 15 accuracy points under noise-free feedback and up to 5 accuracy points under a simple automated binary verification mechanism 🚀.
@inproceedings{liao2024feedback, author = {Liao, Yuan-Hong and Mahmood, Rafid and Fidler, Sanja and Acuna, David}, title = {Can Large Vision-Language Models Correct Semantic Grounding Errors By Themselves?}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, month = jun, year = {2025}, url = {https://arxiv.org/abs/2404.06510}, }


2024
- Reasoning Paths with Reference Objects Elicit Quantitative Spatial Reasoning in Large Vision-Language ModelsYuan-Hong Liao, Rafid Mahmood , Sanja Fidler , and David AcunaIn The 2024 Conference on Empirical Methods in Natural Language Processing , Jun 2024
Despite recent advances demonstrating vision-language models’ (VLMs) abilities to describe complex relationships in images using natural language, their capability to quantitatively reason about object sizes and distances remains underexplored. In this work, we introduce a manually annotated benchmark, Q-Spatial Bench, with 271 questions across five categories designed for quantitative spatial reasoning and systematically investigate the performance of state-of-the-art VLMs on this task. Our analysis reveals that reasoning about distances between objects is particularly challenging for SoTA VLMs; however, some VLMs significantly outperform others, with an over 40-point gap between the two best performing models. We also make the surprising observation that the success rate of the top-performing VLM increases by 19 points when a reasoning path using a reference object emerges naturally in the response. Inspired by this observation, we develop a zero-shot prompting technique, SpatialPrompt, that encourages VLMs to answer quantitative spatial questions using reference objects as visual cues. By instructing VLMs to use reference objects in their reasoning paths via SpatialPrompt, Gemini 1.5 Pro, Gemini 1.5 Flash, and GPT-4V improve their success rates by over 40, 20, and 30 points, respectively. We emphasize that these significant improvements are obtained without needing more data, model architectural modifications, or fine-tuning.
@inproceedings{liaos2024reasoning, title = {Reasoning Paths with Reference Objects Elicit Quantitative Spatial Reasoning in Large Vision-Language Models}, author = {Liao, Yuan-Hong and Mahmood, Rafid and Fidler, Sanja and Acuna, David}, booktitle = {The 2024 Conference on Empirical Methods in Natural Language Processing}, year = {2024}, url = {https://arxiv.org/abs/2409.09788}, } -
 Translating Labels to Solve Annotation Mismatches Across Object Detection DatasetsYuan-Hong Liao, David Acuna , Rafid Mahmood , James Lucas , Viraj Uday Prabhu , and Sanja FidlerIn The Twelfth International Conference on Learning Representations , Jun 2024
Translating Labels to Solve Annotation Mismatches Across Object Detection DatasetsYuan-Hong Liao, David Acuna , Rafid Mahmood , James Lucas , Viraj Uday Prabhu , and Sanja FidlerIn The Twelfth International Conference on Learning Representations , Jun 2024In object detection, varying annotation protocols across datasets can result in annotation mismatches, leading to inconsistent class labels and bounding regions. Addressing these mismatches typically involves manually identifying common trends and fixing the corresponding bounding boxes and class labels. To alleviate this laborious process, we introduce the label transfer problem in object detection. Here, the goal is to transfer bounding boxes from one or more source datasets to match the annotation style of a target dataset. We propose a data-centric approach, Label-Guided Pseudo-Labeling (LGPL), that improves downstream detectors in a manner agnostic to the detector learning algorithms and model architectures. Validating across four object detection scenarios, defined over seven different datasets and three different architectures, we show that transferring labels for a target task via LGPL consistently improves the downstream detection in every setting, on average by 1.88 mAP and 2.65 AP^75. Most importantly, we find that when training with multiple labeled datasets, carefully addressing annotation mismatches with LGPL alone can improve downstream object detection better than off-the-shelf supervised domain adaptation techniques that align instance features.
@inproceedings{liao2024translating, title = {Translating Labels to Solve Annotation Mismatches Across Object Detection Datasets}, author = {Liao, Yuan-Hong and Acuna, David and Mahmood, Rafid and Lucas, James and Prabhu, Viraj Uday and Fidler, Sanja}, booktitle = {The Twelfth International Conference on Learning Representations}, year = {2024}, url = {https://openreview.net/forum?id=ChHx5ORqF0}, }


2023
-
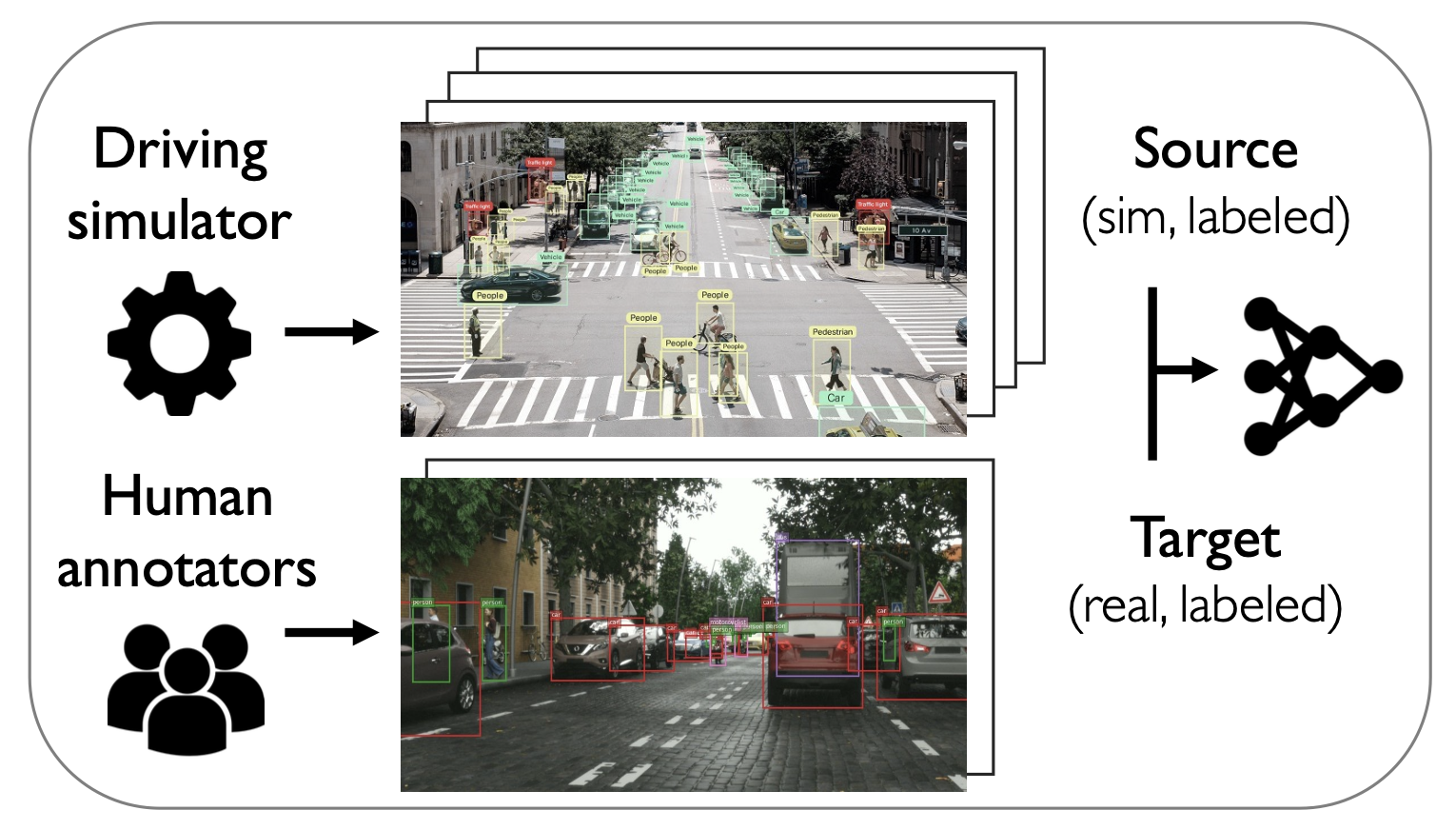 Bridging the Sim2Real gap with CARE: Supervised Detection Adaptation with Conditional Alignment and ReweightingViraj Uday Prabhu , David Acuna , Rafid Mahmood , Marc T. Law , Yuan-Hong Liao, Judy Hoffman , Sanja Fidler , and James LucasTransactions on Machine Learning Research, Jun 2023
Bridging the Sim2Real gap with CARE: Supervised Detection Adaptation with Conditional Alignment and ReweightingViraj Uday Prabhu , David Acuna , Rafid Mahmood , Marc T. Law , Yuan-Hong Liao, Judy Hoffman , Sanja Fidler , and James LucasTransactions on Machine Learning Research, Jun 2023Sim2Real domain adaptation (DA) research focuses on the constrained setting of adapting from a labeled synthetic source domain to an unlabeled or sparsely labeled real target domain. However, for high-stakes applications (e.g. autonomous driving), it is common to have a modest amount of human-labeled real data in addition to plentiful auto-labeled source data (e.g. from a driving simulator). We study this setting of supervised sim2real DA applied to 2D object detection. We propose Domain Translation via Conditional Alignment and Reweighting (CARE) a novel algorithm that systematically exploits target labels to explicitly close the sim2real appearance and content gaps. We present an analytical justification of our algorithm and demonstrate strong gains over competing methods on standard benchmarks.

2021
-
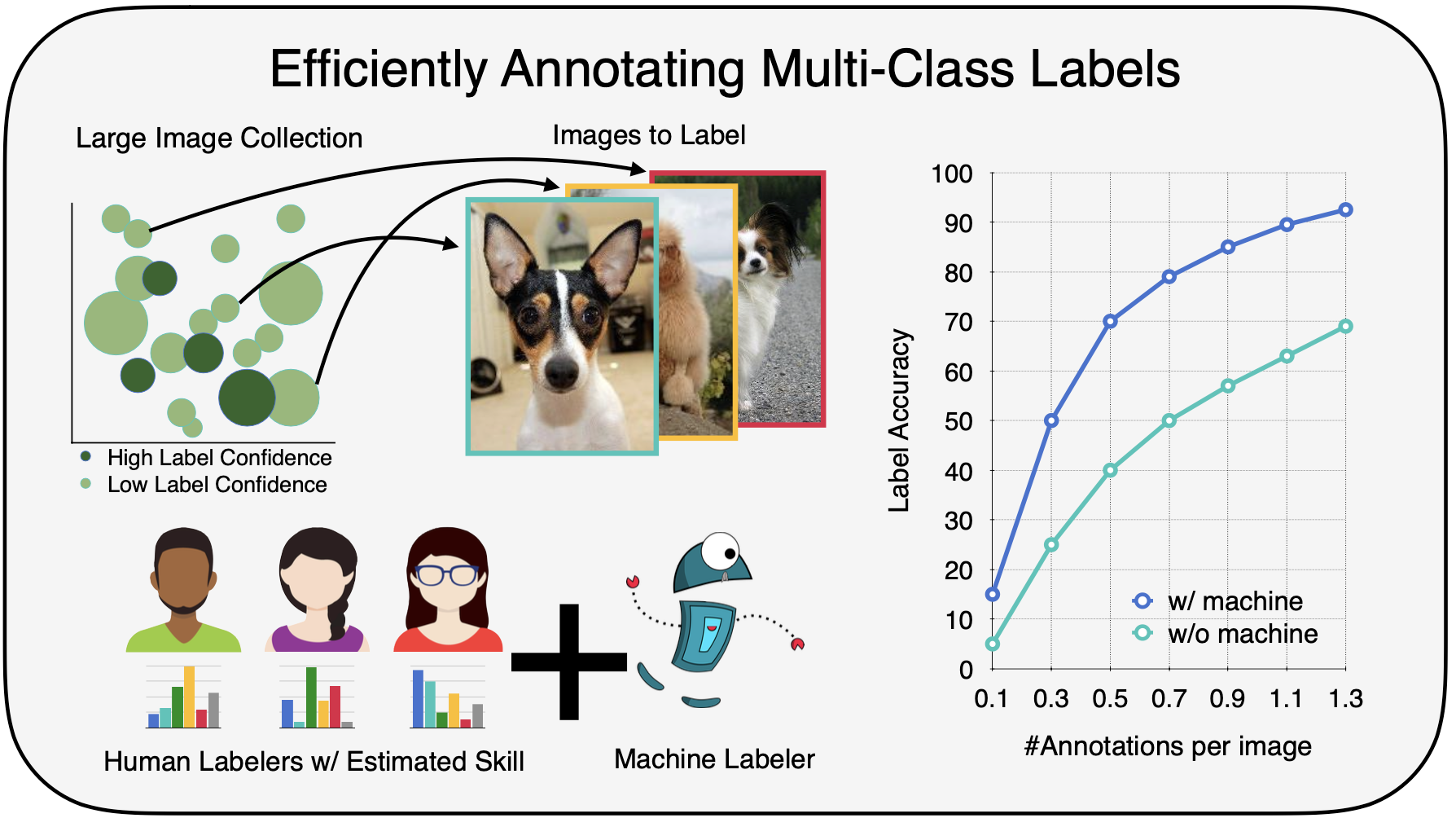 Towards Good Practices for Efficiently Annotating Large-Scale Image Classification DatasetsYuan-Hong Liao, Amlan Kar , and Sanja FidlerIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2021
Towards Good Practices for Efficiently Annotating Large-Scale Image Classification DatasetsYuan-Hong Liao, Amlan Kar , and Sanja FidlerIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2021Data is the engine of modern computer vision, which necessitates collecting large-scale datasets. This is expen- sive, and guaranteeing the quality of the labels is a ma- jor challenge. In this paper, we investigate efficient anno- tation strategies for collecting multi-class classification la- bels for a large collection of images. While methods that ex- ploit learnt models for labeling exist, a surprisingly preva- lent approach is to query humans for a fixed number of labels per datum and aggregate them, which is expensive. Building on prior work on online joint probabilistic mod- eling of human annotations and machine-generated beliefs, we propose modifications and best practices aimed at min- imizing human labeling effort. Specifically, we make use of advances in self-supervised learning, view annotation as a semi-supervised learning problem, identify and mitigate pitfalls and ablate several key design choices to propose ef- fective guidelines for labeling. Our analysis is done in a more realistic simulation that involves querying human la- belers, which uncovers issues with evaluation using exist- ing worker simulation methods. Simulated experiments on a 125k image subset of the ImageNet100 show that it can be annotated to 80% top-1 accuracy with 0.35 annotations per image on average, a 2.7x and 6.7x improvement over prior work and manual annotation, respectively.
@inproceedings{Liao_2021_CVPR, author = {Liao, Yuan-Hong and Kar, Amlan and Fidler, Sanja}, title = {Towards Good Practices for Efficiently Annotating Large-Scale Image Classification Datasets}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, month = jun, year = {2021}, pages = {4350-4359}, } -
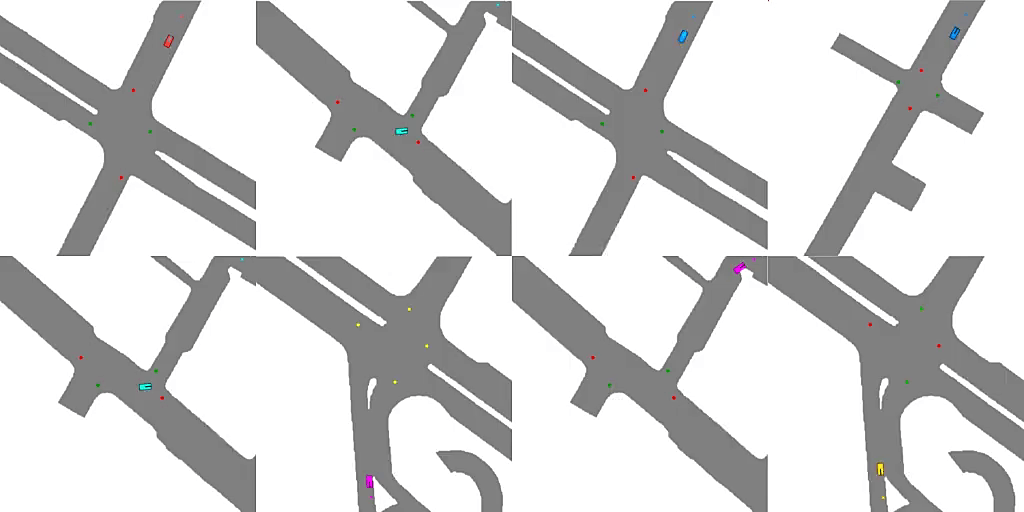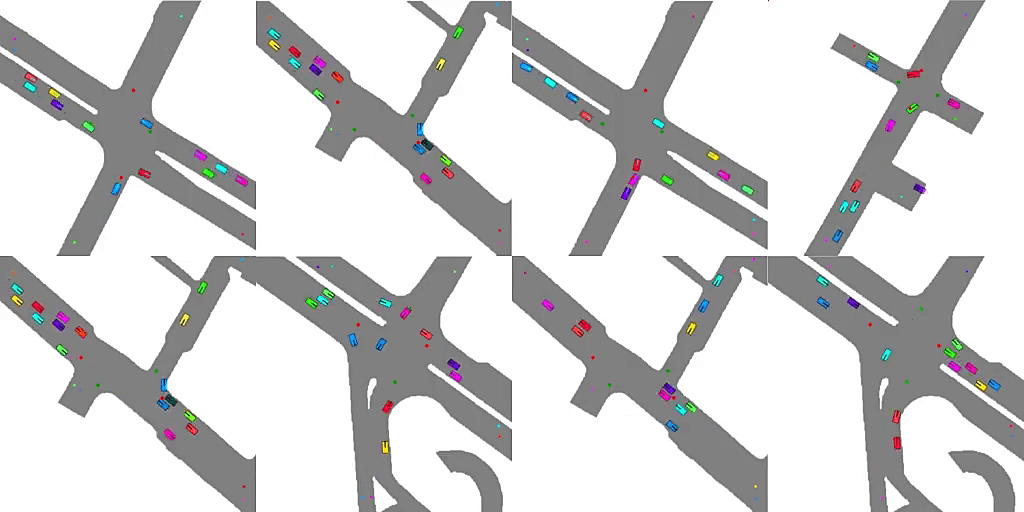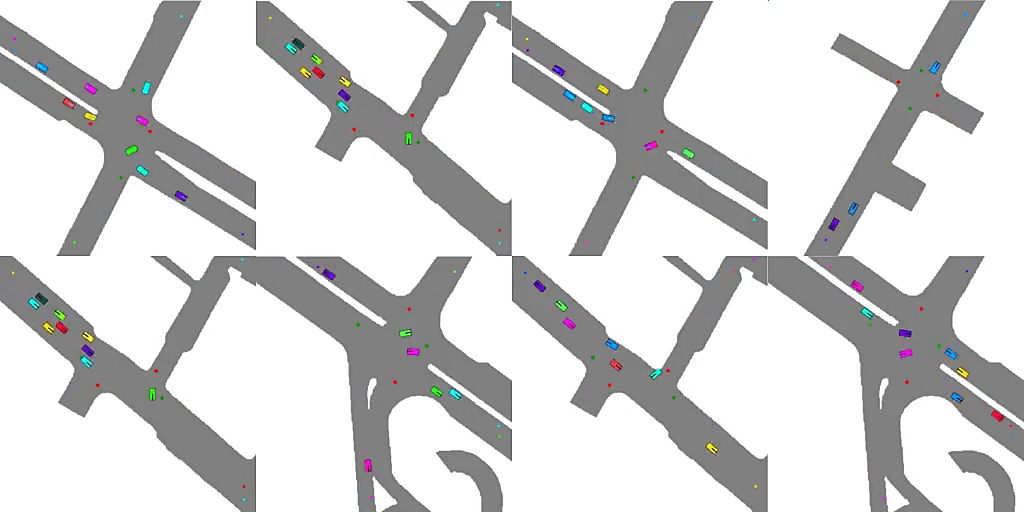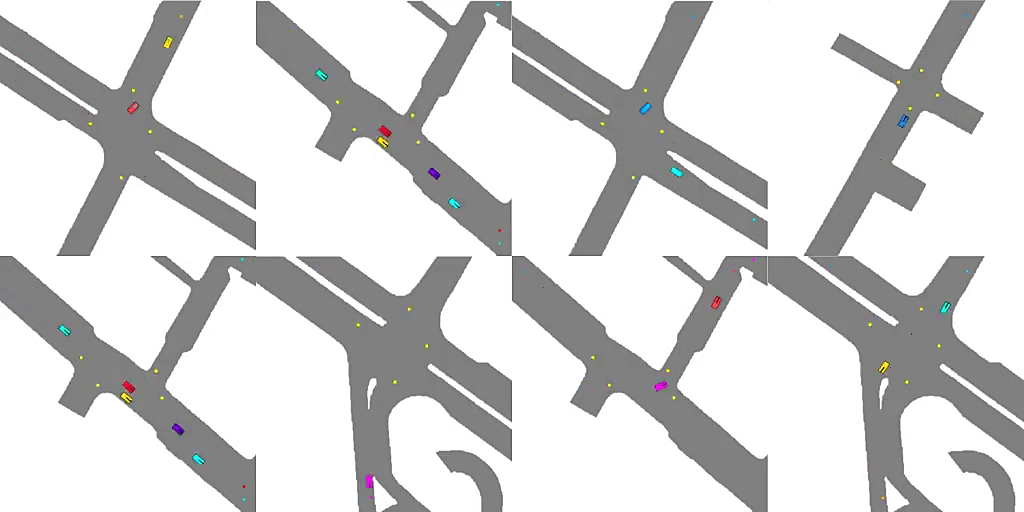 Emergent Road Rules In Multi-Agent Driving EnvironmentsAvik Pal , Jonah Philion , Yuan-Hong Liao, and Sanja FidlerIn International Conference on Learning Representations , Jun 2021
Emergent Road Rules In Multi-Agent Driving EnvironmentsAvik Pal , Jonah Philion , Yuan-Hong Liao, and Sanja FidlerIn International Conference on Learning Representations , Jun 2021For autonomous vehicles to safely share the road with human drivers, autonomous vehicles must abide by specific "road rules" that human drivers have agreed to follow. "Road rules" include rules that drivers are required to follow by law such as the requirement that vehicles stop at red lights as well as more subtle social rules such as the implicit designation of fast lanes on the highway. In this paper, we provide empirical evidence that suggests that instead of hard-coding road rules into self-driving algorithms a scalable alternative may be to design multi-agent environments in which road rules emerge as optimal solutions to the problem of maximizing traffic flow. We analyze what ingredients in driving environments cause the emergence of these road rules and find that two crucial factors are noisy perception and agents’ spatial density. We provide qualitative and quantitative evidence of the emergence of seven social driving behaviors, ranging from obeying traffic signals to following lanes, all of which emerge from training agents to drive quickly to destinations without colliding. Our results add empirical support for the social road rules that countries worldwide have agreed on for safe, efficient driving.
-
 Watch-And-Help: A Challenge for Social Perception and Human-{AI} CollaborationXavier Puig , Tianmin Shu , Shuang Li , Zilin Wang , Yuan-Hong Liao, Joshua B. Tenenbaum , Sanja Fidler , and Antonio TorralbaIn International Conference on Learning Representations , Jun 2021
Watch-And-Help: A Challenge for Social Perception and Human-{AI} CollaborationXavier Puig , Tianmin Shu , Shuang Li , Zilin Wang , Yuan-Hong Liao, Joshua B. Tenenbaum , Sanja Fidler , and Antonio TorralbaIn International Conference on Learning Representations , Jun 2021In this paper, we introduce Watch-And-Help (WAH), a challenge for testing social intelligence in agents. In WAH, an AI agent needs to help a human-like agent perform a complex household task efficiently. To succeed, the AI agent needs to i) understand the underlying goal of the task by watching a single demonstration of the human-like agent performing the same task (social perception), and ii) coordinate with the human-like agent to solve the task in an unseen environment as fast as possible (human-AI collaboration). For this challenge, we build VirtualHome-Social, a multi-agent household environment, and provide a benchmark including both planning and learning based baselines. We evaluate the performance of AI agents with the human-like agent as well as and with real humans using objective metrics and subjective user ratings. Experimental results demonstrate that our challenge and virtual environment enable a systematic evaluation on the important aspects of machine social intelligence at scale.



2019
- Synthesizing Environment-Aware Activities via Activity SketchesYuan-Hong Liao, Xavier Puig , Marko Boben , Antonio Torralba , and Sanja FidlerIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Jun 2019
In order to learn to perform activities from demonstra- tions or descriptions, agents need to distill what the essence of the given activity is, and how it can be adapted to new environments. In this work, we address the problem of environment-aware program generation. Given a visual demonstration or a description of an activity, we gener- ate program sketches representing the essential instructions and propose a model to transform these into full programs representing the actions needed to perform the activity un- der the presented environmental constraints. To this end, we build upon VirtualHome to create a new dataset VirtualHome-Env, where we collect program sketches to represent activities and match programs with environments that can afford them. Furthermore, we construct a knowledge base to sample realistic environments and another knowledge base to seek out the programs under the sampled environments. Finally, we propose ResActGraph, a network that generates a program from a given sketch and an environment graph and tracks the changes in the environment induced by the program.
@inproceedings{Liao_2019_CVPR, author = {Liao, Yuan-Hong and Puig, Xavier and Boben, Marko and Torralba, Antonio and Fidler, Sanja}, title = {Synthesizing Environment-Aware Activities via Activity Sketches}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, month = jun, year = {2019} }
2018
- Multi-view to Novel view: Synthesizing novel views with Self-Learned ConfidenceShao-Hua Sun , Minyoung Huh , Yuan-Hong Liao, Ning Zhang , and Joseph J. LimIn Proceedings of the European Conference on Computer Vision (ECCV) , Sep 2018
2017
- Tactics of Adversarial Attack on Deep Reinforcement Learning AgentsYen-Chen Lin , Zhang-Wei Hong , Yuan-Hong Liao, Meng-Li Shih , Ming-Yu Liu , and Min SunIn Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI-17 , Sep 2017
We introduce two tactics, namely the strategically-timed attack and the enchanting attack, to attack reinforcement learning agents trained by deep reinforcement learning algorithms using adversarial examples. In the strategically-timed attack, the adversary aims at minimizing the agent’s reward by only attacking the agent at a small subset of time steps in an episode. Limiting the attack activity to this subset helps prevent detection of the attack by the agent. We propose a novel method to determine when an adversarial example should be crafted and applied. In the enchanting attack, the adversary aims at luring the agent to a designated target state. This is achieved by combining a generative model and a planning algorithm: while the generative model predicts the future states, the planning algorithm generates a preferred sequence of actions for luring the agent. A sequence of adversarial examples is then crafted to lure the agent to take the preferred sequence of actions. We apply the proposed tactics to the agents trained by the state-of-the-art deep reinforcement learning algorithm including DQN and A3C. In 5 Atari games, our strategically-timed attack reduces as much reward as the uniform attack (i.e., attacking at every time step) does by attacking the agent 4 times less often. Our enchanting attack lures the agent toward designated target states with a more than 70% success rate. Example videos are available at http://yclin.me/adversarial_attack_RL/.
- Leveraging Video Descriptions to Learn Video Question AnsweringKuo-Hao Zeng , Tseng-Hung Chen , Ching-Yao Chuang , Yuan-Hong Liao, Juan Carlos Niebles , and Min SunProceedings of the AAAI Conference on Artificial Intelligence, Feb 2017
- Show, Adapt and Tell: Adversarial Training of Cross-Domain Image CaptionerTseng-Hung Chen , Yuan-Hong Liao, Ching-Yao Chuang , Wan-Ting Hsu , Jianlong Fu , and Min SunIn Proceedings of the IEEE International Conference on Computer Vision (ICCV) , Oct 2017